
The discoveries from my Salesforce journey
As a beginning Salesforce Developer I stumbled upon some limitations Apex confronts me with.
I was used to write any code that will just run when it compiles. If I want to query millions of records from a database and modify each record I would just do so in Java and C#. If this process takes a day to complete, it will simply be so… or I could even create real time 3D games running at 90 frames per second in a Virtual Reality environment. With Apex this is different and at first I had troubles adjusting myself to this language as I saw mostly limitations.
Now, after my first assignment for a client I see the possibilities. During this journey I developed a generalized solution for working with large volumes of data within Salesforce using Apex.
The motivation: taking care of duplications
For a client I had to perform a data migration from multiple databases to Salesforce. Each database holds data for Account, Contact and Candidate objects. It is also possible that the data from these databases have an overlap, which means double records can occur in Salesforce after the migration. I decided that I should take care of ‘double’ records after the migration, because it would be too complex to deduplicate the data between each of the databases.
Later, after the migration to Salesforce, I had to select all the duplicate records. I sat down with the client to discuss how we could recognize a duplicate record and came to the following duplicate strategy for the Account object: “An Account is considered a duplicate when the Name and the ShippingCity matches another.”
Furthermore, sometimes an Account name can be written in different ways like:“ABSI”, “absi”, “absi N.V.”, “ABSI n.v.”, etc. We decided that we should select all Accounts and use some String functions to modify the Account names and shipping cities to all lowercase and remove special characters like dots and commas and also remove company additions like ‘bv’ or ‘nv’. This way we could compare the Accounts easily.

Now we knew how to recognize duplicate Accounts, I was eager to write my first code snippets that would actually be used in a production environment. I had thought out the following strategy to select and de-duplicate all the Accounts:
- Select all Accounts
- Use String functions to filter out the duplicates
- Select all Note objects related to the duplicate Accounts
- Select all Contact objects related to the duplicate Accounts
- Select all Job objects related to the duplicate Accounts
- Reparent all Notes, Contacts and Jobs to a ‘leading’ Account object
- Delete the remaining Accounts (i.e. Accounts that are not leading)
So, I started writing my first queries to select the Accounts, Notes, Contacts and Jobs until I stumbled upon the following Salesforce error message: System.LimitException: Too many query rows: 50001

Uuhhh… Then how can I ever de-duplicate all Accounts? I cannot limit the size of my Account query, one Account could be in the first batch and a duplicate one in the second batch. I do not want to miss these out. Also, how many accounts can I select i.e. how big can my batch size be before I run in another LimitException? Notice that I do not know up-front how many Notes, Contacts and Jobs are related to each Account in a batch.
Moreover, the LimitException might not be the only exception I could run in. Performing (complex) actions over many records also takes time! I’m pretty sure sooner or later I will hit the CPU Limit, as I have noticed Apex is not the fastest…
To give you an idea, in the org there are:
- 30.000 Accounts
- 70.000 Contacts
- 5.000 Jobs
- 800.000 Notes
No wonder I reached the 50.000 query limit with these amounts…
Looking for a solution to solve my problem, I searched the internet and found the Database.Batchable interface. I won’t go into detail too much, but using this interface you can query as much as 50 million records! The catch is, this interface uses Asynchronous methods. So let’s say, if I want to select all Accounts and all related Notes, Contacts and Jobs. I need to select the Accounts and then wait for this asynchronous method to complete before selecting the related objects. Therefore, you cannot do the following (pseudo-code):
firstBatch = executeBatch(“SELECT Id, Name, ShippingCity FROM Account”);
accountIds = firstBatch.Result;
secondBatch = executeBatch(“SELECT Id, ParentId FROM Note WHERE Id IN :accountIds”);
You cannot execute above code because the ‘firstBatch’ is still being executed (or did not even begin yet) when you start the second batch. When you try to execute the second batch, the result list with accountIds is still empty. You need some way to wait for the first batch to complete and then start the next one, using the result of the first.
Luckily for me the Batchable interface looks as follows:

It has a ‘finish’ method! I could just create a ‘chain’ of classes implementing the batchable interface and each class could call the next in line at the end of its finish method. But wait a minute… This will make each chain only suitable for one use case only… And you need so many implementations of this interface for each use case… I don’t like to do so much work and where I come from I would get lashes when I created a system that can only perform one action and serve only one very specific purpose. Can’t I make this more flexible? Of course I can!
The solution: my generic framework
I figured I needed a reusable implementation of the standard Apex Batchable interface. Let’s call this the ‘BatchProcessor’ (I). Because, it actually processes the (batch)result of a query. I also wanted a class that keeps track of the batches that should be processed and that would know when what batch should be executed. For my deduplication use case I call this class the: ‘DeduplicateAccountsProcess’ (II). A process should at least contain a ‘NextStep’ (III) method. This method can be called to let the process know the prior batch execution has finished.
If we model this relationship, it looks like this: hier YourProcessImplementation

Inside the DeduplicateAccountsProcess class I can hold all needed variables, queries and the state of the whole process for my use case. Just change the ‘IProcess’ interface implementation class for a ‘WhatEverYouWantProcess’ and you have yourself a process that can serve another use case.
A template of an example Process class is shown below:
I wrote the BatchProcessor so that you can even pass a parameter with ids for your queries. This ids parameter will auto fill in the query. However, for more complex queries you might still need another Database.Batchable interface implementation. Apex does not support optional method parameters, which could be helpful here. There is still one catch in the above presented solution. Inside the execute method of the BatchProcessor, we might need to perform different actions for different batches to process. When processing Accounts, we might want to store some account variables for example. When processing an other type of object, you might want to store other variables. Why not create an abstract class for it? I call this abstract class a ‘BatchAction’.
A BatchAction holds the query for retrieving the objects you want to process, together with an optional ids variable. Furthermore, the BatchAction abstract class has an execute method in which you can perform specific processing actions. In UML the class looks like this:
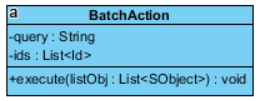
The BatchProcessor can now use any implementation of a BatchAction and IProcess to perform custom queries and execution methods and is reusable for different processes (the code is also very clean!): To create a process for your own use case you can now just override the BatchAction class and implement the IProcess interface. Pass these two classes in a BatchProcessor and you’re all set up.
In UML the final result looks like this:
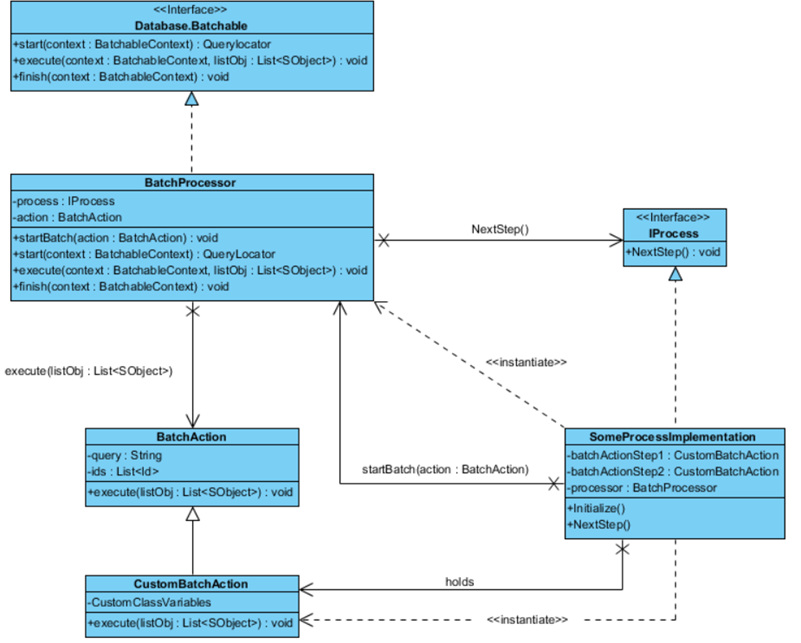
Using this framework you can perform almost any data manipulation with large volumes of records. You could also implement some common or generic BatchActions that you can reuse for other use cases. An example of such a BatchAction could be to select unique identifiers for an Object in your Salesforce org. These identifiers could then be used for a more specific task.
Eager to try this framework yourself? You can find the full code here.
This article was written by Christiaan van Walree.